File structure¶
Scryber expects all content to be in valid XHTML structrure. Tags must be properly closed, and ampersands (&) must either be escaped or valid html character notations (& " etc.)
Example¶
<?xml version="1.0" encoding="utf-8" ?>
<?scryber append-log='true' log-level='Messages' parser-log='true' ?>
<!DOCTYPE HTML>
<html xmlns='http://www.w3.org/1999/xhtml'>
<head>
<title>Hello World</title>
<link rel="stylesheet" href="https://fonts.googleapis.com/css2?family=Fraunces:ital,wght@0,400;0,700;1,400;1,700&display=swap" />
<style>
p {
font-family: Fraunces, 'Times New Roman', Times, serif;
font-size: 40pt;
border-bottom-color: aliceblue;
}
</style>
</head>
<body>
<header>
<div class="pghead">Page Header</div>
</header>
<div style='padding:10px; text-align:center'>
<p>Hello World from scryber.</p>
</div>
</body>
</html>
At the top of the file scryber has it’s own optional processing instuctions to specify log levels and output. This is so you can quickly and easily check what is actually going on under the hood.
The DOCTYPE is not required, and if present will be ignored in preference to the xmlns (next).
The html tag has the xmlns attribute - this tells scryber to expect an XHTML formatted document, rather than any other document description. It is required, although you can use prefixes and any other supported namespaces (see Drawing with SVG)
The rest of the document follows the standard html structure, which is discussed in detail below.
Scryber processing instruction¶
The following are the supported options on the processing instruction.
- ‘append-log’ - Controls the tracing log output for a single document
- ‘log-level’ - This is an enumeration of the granularity of the logging performed on the pdf file. Values supported (from least to most) are
- ‘parser-log’ - Controls the logging from the xml parser.
- ‘parser-culture’ - specifies the global culture settings when parsing a file for interpreting dates and number formats in the content. e.g.
- ‘parser-mode’ - Defines how errors will be recorded if unknown or invalid attributes values are encountered.
See Scryber Trace Log for a detailed explanation of the tracing and logging capabilities in scryber which is really useful.
XML Namespaces¶
Scryber is dynamic and extensible. The xml namespaces refers directly to namespaces (and assemblies) in the library, and is reqiured. If you don’t have a known namepsace, then you will get an error. There are 2 primary namespaces in use with xhtml documents.
- http://www.w3.org/1999/xhtml
- This is the main visual and structural components in an html file or document.
- see Standard document components for a description of each of these.
- http://www.w3.org/2000/svg
- These are the svg graphics components. e.g. svg, path, line, rect
- see Drawing with SVG for a description of each of these.
For more information on how these are mapped, and also adding your own namespaces see Namespaces and their Assemblies along with scryber_configuration
Html header¶
In the html header. the following tags are supports as direct mappings to the PDF document information.
<head>
<title>My Document</title>
<base href='https://raw.githubusercontent.com/richard-scryber/scryber.core/master/Scryber.Core.UnitTest/Content/HTML/' />
<meta name='author' content='Richard Hewitson' />
<meta name='description' content='This is the subject' />
<meta name='keywords' content='Scryber; Document Info; Properties' />
<meta name='generator' content='Scryber Documentation' />
<meta name='print-restrictions' content='none' />
</head>
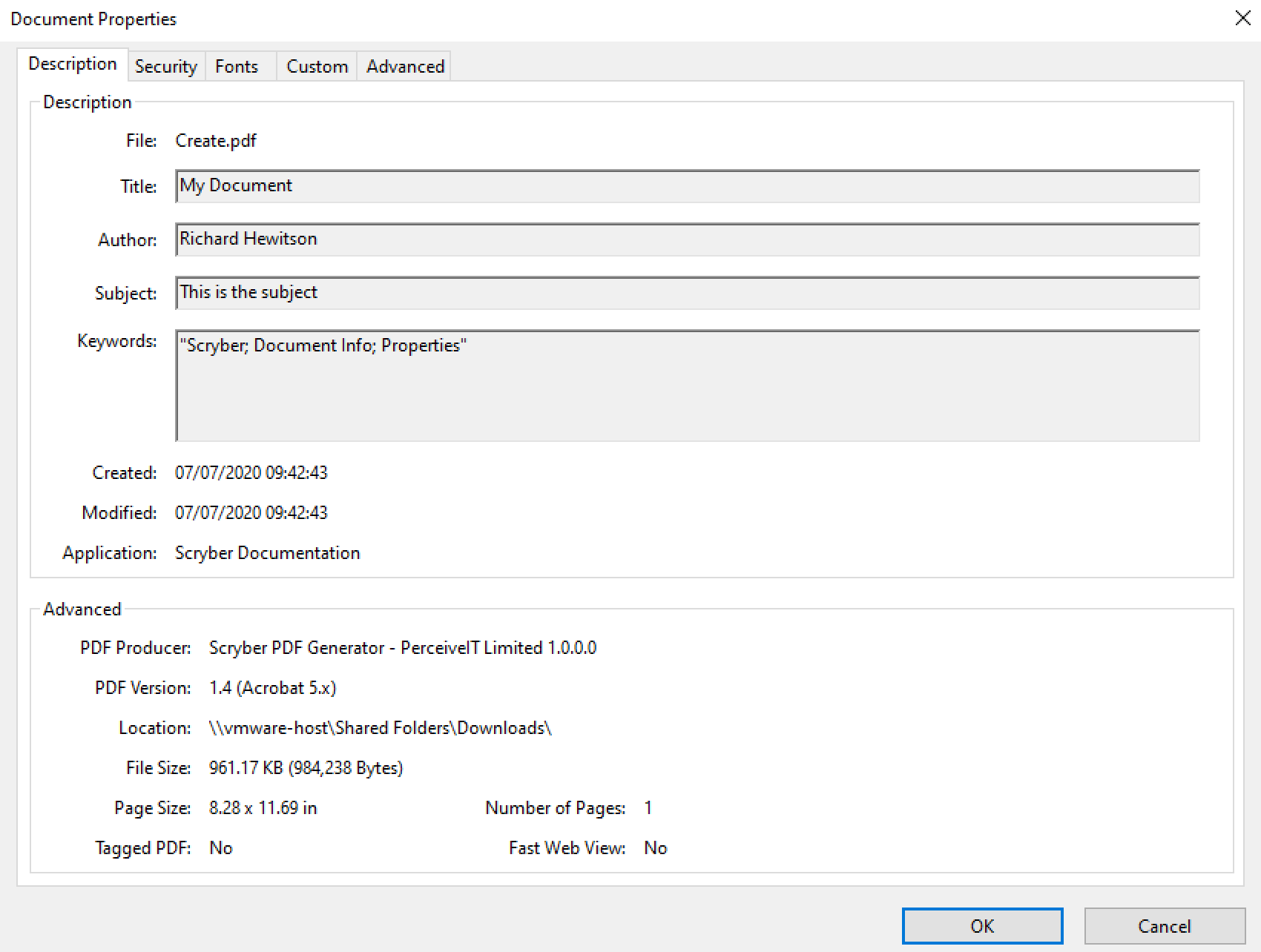
The base path will set the root path to any relative resources in the rest of the document.
The header also supports the <link> and <style> elements discussed below, although these are happily supported elsewhere too. It is only the meta and title elements that need to be in the html head. The print-restrictions applies security to the document as discussed in Securing Documents
Html link element¶
If a <link> is included in the html file (in the head preferably). Then it must have the ‘rel’ attribute of stylesheet and a ‘href’ to a valid css file.
Note
If the rel attribute is not set, then it is assumed to be a stylesheet, and loaded. But may not be able to be parsed.
The href can either be relative to the current file, or a full absolute url to a file.
Html style element¶
Scryber supports many of the standard html css styles. It also supports the use of @media at-rules so that css can be applied to only the document output.
More information on what css selectors are supported and the css properties see Styles in your template
The body¶
The body element is the visual content of the document, as 1 or more pages of content with various sizes and many features. It also suppots the header and footer elements for creating repeating headers and footers.
See Standard document components for a more general introduction to the visual content supported and Supported Html Tags and Styles for a full list of all the tags scyber currently supports.