1.6. Parsing documents from content¶
When you parse the contents of an file, or a stream or a reader, Scryber builds a full object model of the content plus any referenced content. As the parser is based around XML it is important that all content is valid - it does not like unclosed tags or elements.
1.6.1. Content namespaces¶
As the most basic example
<!-- /Templates/Overview/SimpleParsing.html -->
<!DOCTYPE HTML >
<html lang='en' xmlns='http://www.w3.org/1999/xhtml' >
<head>
<title>Hello World</title>
</head>
<body>
<div style='padding:10px'>Hello World.</div>
</body>
</html>
//Scryber.UnitSamples/OverviewSamples.cs
public void SimpleParsing()
{
var path = GetTemplatePath("Overview", "SimpleParsing.html");
using (var doc = Document.ParseDocument(path))
{
using (var stream = GetOutputStream("Overview", "SimpleParsing.pdf"))
{
doc.SaveAsPDF(stream);
}
}
}
Would be parsed into the following Document Object Model
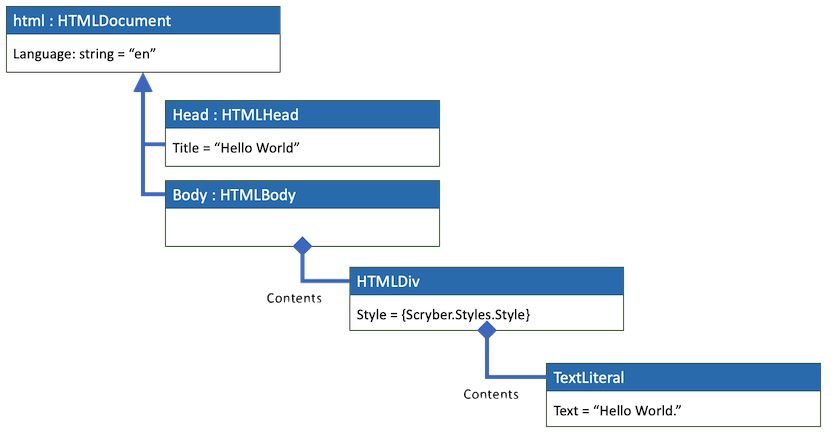
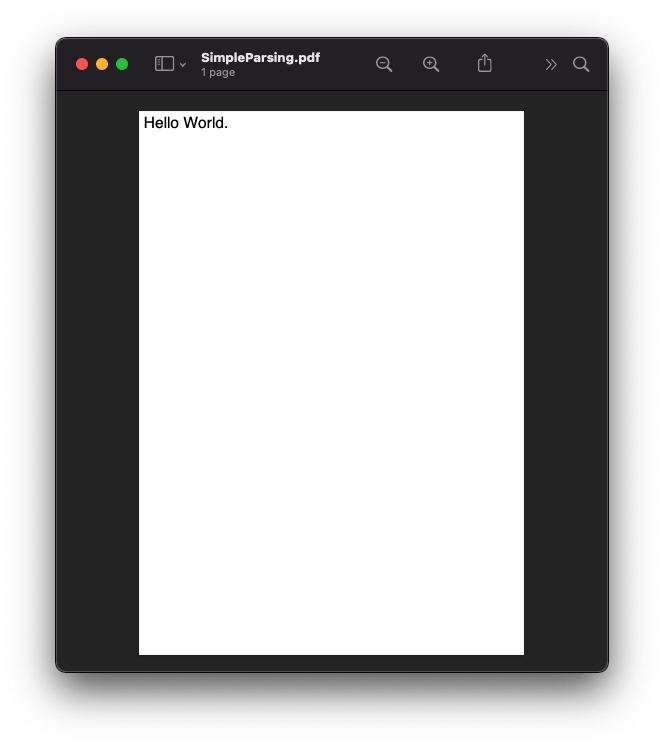
And the output would be
The namespace for an element must be known to the parser. For most XHTML templates this will be the standard XML Namespace (xmlns) http://www.w3.org/1999/xhtml
This namespace is mapped directly onto the library assembly and namespace Scryber.Html.Components, Scryber.Components
In the library there is a class called HTMLDocument that is decorated with the PDFParsableComponent attribute with a name of ‘html’.
This is how the parser knows that when it sees an XML element called html it should create an instance of the Scryber.Html.Components.HTMLDocument class.
This class has a couple of properties on it for Head and Body that are decorated with the PDFElement attribute with names head and body respectively.
So the parser knows when it reads elements with this name, the values should be set as instances of the classes HTMLHead and HTMLBody.
It also has an attribute for the lang value that will be set.
namespace Scryber.Html.Components
{
[PDFParsableComponent("html")]
public class HTMLDocument : Document
{
[PDFElement("head")]
public HTMLHead Head
{
get;
set;
}
[PDFElement("body")]
public HTMLBody Body
{
get ;
set ;
}
[PDFAttribute("lang")]
public string Language
{
get;
set;
}
.
.
.
}
}
And so it goes on into the rest of the xml, reading elements and attributes, and trying to set the values to components or property values.
1.6.2. Parsing documents from files¶
The easiest way to parse any xml content is to use the various static methods on the Scryber.Components.Document class.
There are 2 variants called ParseDocument and Parse.
ParseDocument has 6 overloads and the content parsed must have a root object that is (or inherits from) Scryber.Components.Document
The simplest is to load directly from a file
//using Scryber.components
string filepath = GetPathToFile();
var doc = Document.ParseDocument(filepath);
This reads the file from the stream and will resolve any references to relative content (images, stylesheets, etc) based on the filepath.
1.6.3. Parsing documents from streams¶
If you want to load content dynamically from a stream then you can use the overloads that take a stream. An enumeration value for ParseSourceType must be provided, and an optional path value, so the parser can know where other references may reside.
//from a stream with no references
using(var stream = GetMyDocumentContent())
{
doc = Document.ParseDocument(stream, PaseSourceType.DynamicContent);
}
If the stream will contain relative path references to other content such as stylesheets or embedded content then a path should be provided. If no path is provided then content will be looked for relative to any basePath specified in the source stream. If no base path is provided then content will be looked for relative to the current executing assembly.
//from a stream where references are known to be stored
var path = "C:/MyFiles/BasePath";
using(var stream = GetMyDocumentContent())
{
doc = Document.ParseDocument(stream, path, PaseSourceType.DynamicContent);
}
The options for the content can be any of the following.
- A
System.IO.Streamor one of its sublcasses. - A
System.IO.TextReaderor one of its subclasses. - A
System.XML.XmlReaderor one of its subclasses.
Ultimately the content should be valid XML that can be read.
For example, using an XmlReader
//using System.Xml.Linq
//Scryber.UnitSamples/OverviewSamples.cs
public void XLinqParsing()
{
XNamespace ns = "http://www.w3.org/1999/xhtml";
var html = new XElement(ns + "html",
new XElement(ns + "head",
new XElement(ns + "title",
new XText("Hello World"))
),
new XElement(ns + "body",
new XElement(ns + "div",
new XAttribute("style", "padding:10px"),
new XText("Hello World."))
)
);
using (var reader = html.CreateReader())
{
//passing an empty string to the path as we don't have images or other references to load
using (var doc = Document.ParseDocument(reader, string.Empty, ParseSourceType.DynamicContent))
{
using (var stream = GetOutputStream("Overview", "XLinqParsing.pdf"))
{
doc.SaveAsPDF(stream);
}
}
}
}
Or from a string itself
//using System.IO
//Scryber.UnitSamples/OverviewSamples.cs
public void StringParsing()
{
var title = "Hello World";
var src = @"<html xmlns='http://www.w3.org/1999/xhtml' >
<head>
<title>" + title + @"</title>
</head>
<body>
<div style='padding: 10px' >" + title + @".</div>
</body>
</html>";
using (var reader = new StringReader(src))
{
using (var doc = Document.ParseDocument(reader, string.Empty, ParseSourceType.DynamicContent))
{
using (var stream = GetOutputStream("Overview", "StringParsing.pdf"))
{
doc.SaveAsPDF(stream);
}
}
}
}
All 3 methods create exactly the same document. It also allows for building dynamic documents at runtime - but there are other ways :see::7_parameters_and_expressions
1.6.4. Building in code¶
The template parsing engine is both flexible and extensible, but it does not have to be used. Scryber components are real object classes, they have properties and methods along with inner collections.
We can just as easily create the document using a method.
//using Scryber.Components
//using Scryber.Drawing
//Scryber.UnitSamples/OverviewSamples.cs
protected Document GetHelloWorld()
{
var doc = new Document();
doc.Info.Title = "Hello World";
var page = new Page();
doc.Pages.Add(page);
var div = new Div() { Padding = new PDFThickness(10) };
page.Contents.Add(div);
div.Contents.Add(new TextLiteral("Hello World"));
return doc;
}
public void DocumentInCode()
{
using (var doc = GetHelloWorld())
{
using (var stream = GetOutputStream("Overview", "CodedDocument.pdf"))
{
doc.SaveAsPDF(stream);
}
}
}
This works well, and may have benefits for your implementations, but ultimately could become very complex and difficult to maintain.
1.6.5. Embedding other content¶
Including content from other sources (files) is easy within the template by using the <embed> element with the src attribute set to the name of the source file.
This can either be a relative or an absolute path to the content to be included.
<embed src='./fragments/tsandcs.html' />
The content will be loaded by the parser syncronously rather than later at load time, which is the case for css stylesheets and images. This is to ensure there is a full file content to be parsed.
The embedded content should be a fragment of valid xhtml / xml rather than a full html file. The namespaces are required in the embessed file, as well.
<!-- /Templates/Overview/Fragments/TsAndCs.html -->
<!-- Standard terms and conditions, with namespace -->
<div id='MyTsAndCs' xmlns='http://www.w3.org/1999/xhtml'>
<p>1. We will look after you</p>
<p>2. If you look after us</p>
</div>
<!DOCTYPE HTML>
<html lang='en' xmlns='http://www.w3.org/1999/xhtml'>
<head>
<title>Hello World</title>
</head>
<body>
<div style='padding:10px'>Hello World.</div>
<!-- embedded content within a div -->
<div style="border:solid 1px black; margin:10pt; padding:5pt">
<embed src="./fragments/tsandcs.html" />
</div>
</body>
</html>
//Scryber.UnitSamples/OverviewSamples.cs
public void EmbedContent()
{
var path = GetTemplatePath("Overview", "EmbeddedContent.html");
using (var doc = Document.ParseDocument(path))
{
//Embedded content is loaded at parse time
var embedded = doc.FindAComponentById("MyTsAndCs") as Div;
Assert.IsNotNull(embedded);
using (var stream = GetOutputStream("Overview", "EmbeddedContent.pdf"))
{
doc.SaveAsPDF(stream);
}
}
}
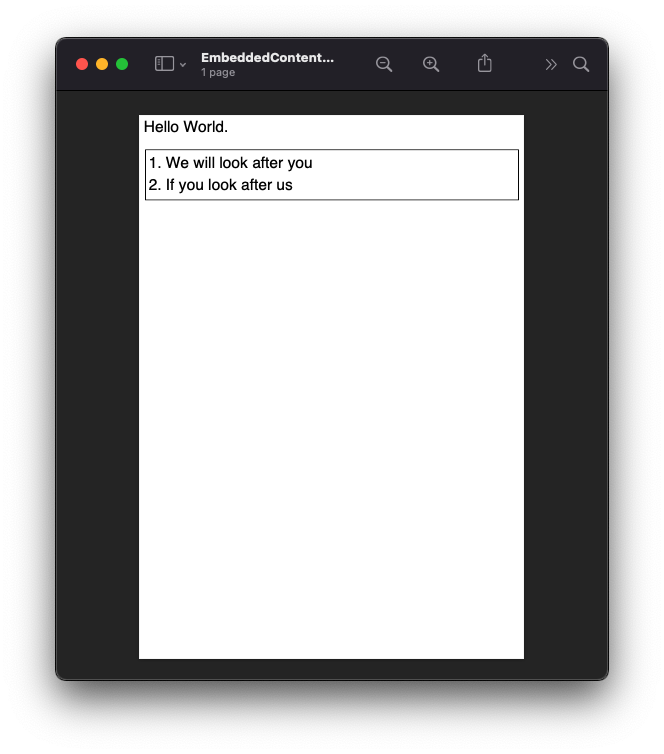
When loading with relative references, the original path to the source file will be used to resolve the location of the embedded source.
As with the examples above - if the content is being parsed dynamically, either the base path to the location sould be specified in the ParseDocument
method, or a PDFReferenceResolver should be provided, as below.
1.6.6. Resolving references¶
The Document.Parse method, and its 12 overloads allows for parsing of any xml content as long as the root component returned implements the IPDFComponent interface.
If there are references to other content, that needs to be resolved at runtime it is also possible to pass a PDFReferenceResolver delegate to the parser so that your
code can load it’s own content and return it.
public delegate IPDFComponent PDFReferenceResolver(string filename, string xpath, PDFGeneratorSettings settings);
This delegate will be called each time a remote reference is found, with the name of the file, and an optional xpath selector. It is upto the implementor to perform the parsing.
For example if we wanted to embed some standard content we could provide our own implementation.
private IPDFComponent CustomResolve(string filepath, string xpath, PDFGeneratorSettings settings)
{
if(filepath == "MyTsAndCs")
{
using(var tsAndCs = LoadTermsStream())
{
//We have our stream so just do the parsing again with the same settings
return Document.Parse(filepath, tsAndCs, ParseSourceType.DynamicContent, CustomResolve, settings);
}
}
else
{
filepath = System.IO.Path.Combine(MyBasePath, filepath);
return Document.Parse(filepath, CustomResolve, settings);
}
}
And our document can reference the custom resolver with the
var doc = Document.Parse(string.Empty, reader, ParseSourceType.DynamicContent, CustomResolve) as Document;
This will allow content from databases, or authenticated feeds to be added, or even transformed and added.
Note
Remember, the content to be parsed MUST be valid XML, including all XML namespaces, OR wrapped in an xml element.
It is also possible to return just coded objects in the return of the reference resolver, and the PDFReferenceResolver delegate can be any instance.
//using Scryber.Components
//using Scryber.Drawing
private IPDFComponent CustomResolve(string filepath, string xpath, PDFGeneratorSettings settings)
{
if(filepath == "MyTsAndCs")
{
var p = new Paragraph(){ BackgroundColor = PDFColors.Aqua };
p.Contents.Add(new PDFTextLiteral("These are my terms"));
return p;
}
else
{
filepath = System.IO.Path.Combine(MyBasePath, filepath);
return Document.Parse(filepath, CustomResolve, settings);
}
}
1.6.7. Default namespaces¶
The html and svg namespaces are also automatically added.
- http://www.w3.org/1999/xhtml
- The html components used in scryber. e.g. div, span, section etc.
- It refers to the Scryber.Html.Components namespace in the Scryber.Components assembly (Version=1.0.0.0, Culture=neutral, PublicKeyToken=872cbeb81db952fe)
- http://www.w3.org/2000/svg
- The svg drawing components used in scryber. e.g. ellipse, circle, rect etc.
- It refers to the Scryber.Svg.Components namespace in the Scryber.Components assembly (Version=1.0.0.0, Culture=neutral, PublicKeyToken=872cbeb81db952fe)
See Extending Scryber - TD for more information on how to extend the namespaces used by the parser, and create your own components.
1.6.8. Further reading¶
- Learn about 1.7. Document parameters and binding in the next section.
- For more about code vs templates see XHTML Template
- All the available components see Components overview - TD
- All the available styles see Styles in your template - PD
- Split your files? See 2_document/14_document_references for more on stylesheet links and embedding content.